






PDFTableExtract2 is a command-line program from extracting tables from PDF.
PDFTableExtract2 is fully automatic; it can:
Detect tables on a PDF page (support several tables per page*)
Recognize vertical and horizontal lines
Recognize empty spaces as col/row separators (*)
Detect merged cells (i.e. rowspan and colspan)
Extract the text in each cell
Extract the text ouside tables (*)
Optionnaly, use an OCR program (such as Tesseract) for non-text PDF (*)
Output pseudo-HTML, CSV, JSON or Python lists
PDFTableExtract2 is written in Python 3; it is an improved version of PDF-table-extract from Ashima Research. PDFTableExtract2 has then been improved (in particular features marked with an *) by Jean-Baptiste Lamy at the LIMICS reseach lab, during the VIIIP projects about information on new drugs, founded by ANSM (the French drug agency). It is available under the GNU LGPL licence v3. In case of trouble, please contact Jean-Baptiste Lamy <email on the left column>.
LIMICS University Paris 13, Sorbonne Paris Cité Bureau 149 74 rue Marcel Cachin 93017 BOBIGNY FRANCE
Methods
Table detection is achieved in three steps: detecting lines, dividers and cells:
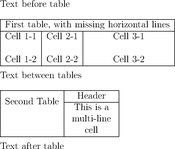
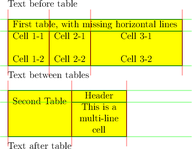
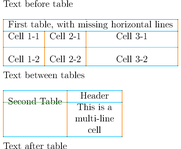
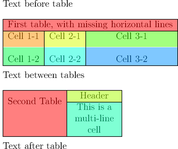
And here is the result in pseudo-HTML:
<?xml version="1.0" encoding="utf-8"?>
<html>
<head><meta charset="utf-8"/></head>
<body>
<div>Text before table</div>
<table border="1">
<tr>
<td colspan="3">First table, with missing horizontal lines</td>
</tr>
<tr>
<td>Cell 1-1</td>
<td>Cell 2-1</td>
<td>Cell 3-1</td>
</tr>
<tr>
<td>Cell 1-2</td>
<td>Cell 2-2</td>
<td>Cell 3-2</td>
</tr>
</table>
<div>Text between tables</div>
<table border="1">
<tr>
<td rowspan="2">Second Table</td>
<td>Header</td>
</tr>
<tr>
<td>This is a multi-line cell</td>
</tr>
</table>
<div>Text after table</div>
</body>
</html>Links
PDFTableExtract2 on BitBucket (development repository): https://bitbucket.org/jibalamy/pdftableextract2