






PDFTableExtract2 est un programme en ligne de commande pour extraire des tableaux à partir de fichiers PDF.
PDFTableExtract2 fonctionnent de manière entièrement automatique ; il peut notamment :
Détecter les tableaux sur une page PDF (il supporte plusieurs tableaux par page*)
Reconnaître les lignes verticales et horizontales
Reconnaître les espaces blancs comme des séparateurs de ligne ou de colonne (*)
Détecter les cellules fusionnées (i.e. rowspan et colspan)
Extraire le texte de chaque cellule
Extraire le texte en-dehors des tableaux (*)
En option, utiliser un programme d'OCR (tel que Tesseract) si le texte est sous forme d'image (*)
Produire une sortie pseudo-HTML, CSV, JSON ou listes Python
PDFTableExtract2 est écrit en Python 3; il s'agit d'une version améliorée de PDF-table-extract d'Ashima Research. PDFTableExtract2 a été amélioré (en particulier les fonctionnalités marquées d'un *) par Jean-Baptiste Lamy au laboratoire de recherche LIMICS, lors du projet VIIIP sur l'information sur les nouveaux médicaments, financé par l'ANSM (Agence Nationale de Sécurité du Médicament et des produits de santé). Il est disponible sous la licence GNU LGPL v3. En cas de problème, merci de contacter Jean-Baptiste Lamy <email dans la colonne de gauche du site>.
LIMICS University Paris 13, Sorbonne Paris Cité Bureau 149 74 rue Marcel Cachin 93017 BOBIGNY FRANCE
Fonctionnement
La détection se fait suivant trois étapes : reconnaissance des lignes, des délimiteurs et des cellules :
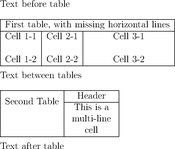
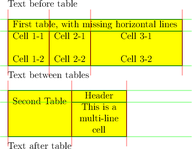
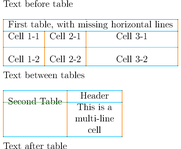
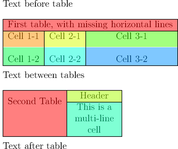
Et voici le résultat produit en pseudo-HTML:
<?xml version="1.0" encoding="utf-8"?>
<html>
<head><meta charset="utf-8"/></head>
<body>
<div>Text before table</div>
<table border="1">
<tr>
<td colspan="3">First table, with missing horizontal lines</td>
</tr>
<tr>
<td>Cell 1-1</td>
<td>Cell 2-1</td>
<td>Cell 3-1</td>
</tr>
<tr>
<td>Cell 1-2</td>
<td>Cell 2-2</td>
<td>Cell 3-2</td>
</tr>
</table>
<div>Text between tables</div>
<table border="1">
<tr>
<td rowspan="2">Second Table</td>
<td>Header</td>
</tr>
<tr>
<td>This is a multi-line cell</td>
</tr>
</table>
<div>Text after table</div>
</body>
</html>Liens
PDFTableExtract2 sur BitBucket (version de dévelopement): https://bitbucket.org/jibalamy/pdftableextract2